About planning a database
A well-designed database promotes consistent data entry and retrieval, and reduces the existence of duplicate data among the database tables. Relational database tables work together to ensure that the correct data is available when you need it. It’s a good idea to plan a database on paper first.
|
1.
|
Determine the purpose for your database, or the problem you want to solve. For example, “to keep a list of my customers,” “to manage my inventory,” or “to grade my students.”
|
|
2.
|
Consider the information you will store in your database. Typically, information falls into broad categories. Accurately identifying these categories is critical to designing an efficient database, because you will store different types and amounts of data in each category. For example, a database intended to track sales has categories such as “products,” “invoices,” and “customers.” A database that records student grades has categories such as “students,” “classes,” and “assignments.”
|
|
3.
|
Once you’ve determined the broad categories, consider how these categories are related. This can be done by writing simple sentences that describe how the categories interact, such as, “teachers teach classes,” “students are assigned to classes,” and “students complete assignments.” Each of these pairs suggests a relationship between the data in one category and the data in the other category.
|
In database terminology, these categories of information are referred to as tables. Tables are used to group data containing a common element or purpose. For example, you might use one table to store names and addresses, while you use another table to store transaction details, such as date of sale, item number, unit price, and so on.
|
•
|
A single table in a single file. Use a single table if you need to track data in one category only, such as names and addresses.
|
|
•
|
Multiple tables in a single file. Use multiple tables if your data is more complex, such as students, classes, and grades.
|
|
•
|
Multiple tables in multiple files. Use multiple files if you need to share the same data among several different database solutions. For example, you can store your tax rates or shipping information in a separate file if you plan to use that information in more than one solution.
|
Use relationships to share data between tables in the same file or with tables in external files. Other database elements, such as scripts and access privileges, are stored at the file level; therefore, some complex solutions will benefit from using multiple files.
Note FileMaker Pro is very flexible, so the decision to store data in a single file or in multiple files is often one of packaging and convenience. Data stored in tables is very easily shared between tables in the same file and tables in external files using relationships, as explained in Working with related tables and files. Other elements, such as scripts and access privileges, are stored at the file level, and because of this some complex solutions will benefit from using multiple files.
|
5.
|
Tip To make it easy to search and sort records, create separate fields for first and last name, titles (like Mr. or Dr.) and items in addresses (city, state or province, country, and postal code). Separating your data into multiple fields at the time of data entry can make it easier to generate future reports. For example, using separate fields to capture transaction details such as the date, item number, quantity, and unit price of each transaction makes it easier to compile summary and subsummary reports at the end of a week, month, or year.
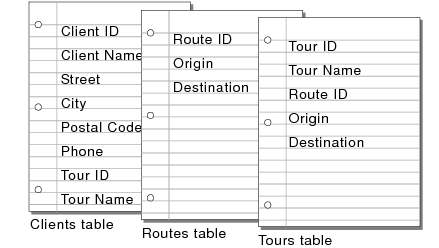
For example, a database for a travel agency might include these tables: a Clients table, which stores client information; a Routes table, which stores route information; and a Tours table, which stores the tours and their current prices.
A Clients table might have fields for a client identification number, and the client’s name, address and phone number. A Routes table might have fields for a route identification number, the departure city, and the destination city. A Tours table might have fields for a tour identification number and tour name.
|
7.
|
Determine the match fields for each table, and circle each one in your plan.
|
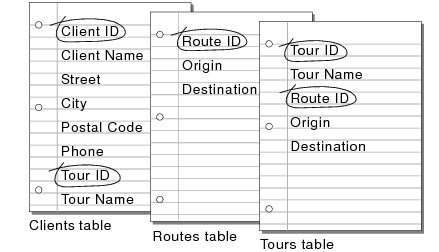
For example, in the Clients table you might want to assign each client a unique, identifying number. You wouldn’t enter a client identification number into the table unless you had a new client to add, so the existence of a client number determines the existence of a record.
|
8.
|
For example, the fields in one record of the Clients table together store all the information about one client.
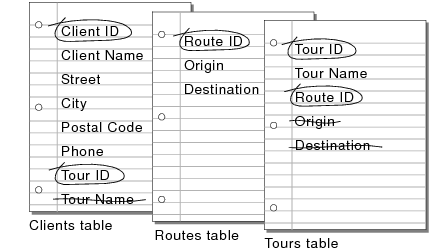
Based on a table’s subject, you can see where it makes sense to store the data and where to use data from a related table. Other than match fields, all fields should appear only once in your database. Cross out occurrences of fields that don’t pertain to the table’s subject.
|
9.
|
Determine the relationships between the tables. In your plan, draw a line from each match field in a table to the corresponding match field in the related table.
|
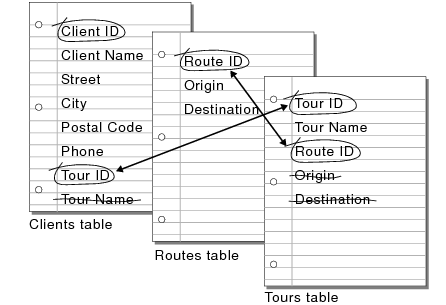
Relationships also make it possible to group your data to resolve complex questions. For example, relationships can be used to determine current inventory levels, sales projections, and other tasks where it is necessary to view data across multiple tables. For more information about relationships, see Working with related tables and files.
|
10.
|
Determine whether you need to share your database with other users, and how they will access the file.
|
|
11.
|
If you’re designing the database for other people to use, show them your paper plan and ask them to review it and suggest any changes.
|
|
12.
|
Consider who will use the database and whether you want to restrict access to it. When you create the database, assign access privileges as needed.
|
|
13.
|
Decide what layouts you need, and plan a separate layout for each task.
|
|
14.
|
Create a form that lists all the files and tables you need and the fields for each table. Also list the forms and reports you will generate from each table.
|
|
16.
|
If you’ve designed the database for others to use, ask a few people to test it. Then, fix any problems they found before you make the database available for everyone to use.
|